SPARKSQL RDF Benchmark.
A systematic Benchmarking on the performance of Spark-SQL for processing Vast RDF datasets
- Home
- Bench-Ranking
- Ranking Criteria
- Ranking Goodness
- Project Source Code
- Results
- Benchmark Datasets
- Download Logs
This project is maintained by DataSystemsGroupUT
Ranking Goodness
A ranking criterion aims at identifying the configurations that have the overall best results. In practice, We can consider a ranking criterion “good” if it does not suggest a low-performing configuration. In other words, we are not interested to be the best at any particular query as long as we are never the worst. Herein, we discuss how can we measure such goodness, i.e., how to evaluate the ranking measure?.
Table of contents:
This problem is well-known in Information Retrieval (IR) applications, where several metrics, e.g., Precision and Recall, are used to validate the ranking. Nevertheless, the main difference between IR and bench-ranking is the lack of ground truth. The most reasonable solution is to employ multiple ranking criteria and compare the prescriptions with the actual experimental results. However, this approach falls back to the problem relates to ranking consensus. Ranking consensus is different from combined ranking. The former is related to choosing between two preference sets, and the latter is about designing a ranking metric that considers multiple dimensions.
Def1: Rank Set
A rank set R is an ordered set of elements ordered by a ranking score. A rank index ri is the index of a ranked element i within a ranking set R , i.e., R|r_i|=i. We denote with R^k the left most subset of R of length k, and we denote with R_x the rank set calculated according to the Rank score R_x.
Goodness Criteria:
In this regards, Bench-ranking proposes to measure the following:
- The ranking confidence:by checking how accurate a ranking criterion of its top-ranked configurations according to the actual query positioning of those configurations.
- The ranking coherence, that is the level of agreement between two ranking sets using different ranking criteria or across different experiments. The invariant in our case is the Scale (across different dataset sizes from 100-to-250, 250-500,100-500M datsets).
1- The Conformance Measure
To measure the confidence, we propose the following approach described by the following equation:
Given the top-k subset of the ranking set R we count how many times its elements occur in the bottom-h subset of the ranking set Q_h(i), which corresponds to the ranking set obtained by using the execution time of query Q_i as ranking criterion, for each query. In other words, we look at the rank of the top-ranked configurations (by a ranking criteria R), and make sure by the above formula that they are not in the bottm-h query positions/ranked configurations. This is computed for all queries in the benchmark. the intuition is the ranking top ranked configuration shouldn’t appear as worst performing for the queries.
Table of best 3 configuration ranked by the criteria Rf,Rp, and Rs (single-dimensional criteria), across our experimental datasets
| Top-3 Configurations | 100M | 250M | 500M | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Rs | b.iii.2 | b.iii.1 | b.iii.4 | b.iii.1 | b.iii.2 | b.iii.3 | b.iii.1 | b.iii.2 | b.iii.4 |
| Rp | a.ii.3 | a.ii.4 | a.ii.5 | a.ii.5 | b.ii.3 | c.ii.3 | c.ii.3 | c.ii.4 | b.ii.5 |
| Rf | a.iii.3 | a.ii.3 | c.ii.3 | a.iii.3 | a.ii.3 | b.ii.4 | a.ii.3 | a.iii.3 | b.i.4 |
Examples of the confidence Calculations
For instance, let’s consider the R_s rank and the 100M dataset evaluation. The top-3 ranked configurations (see the table above) are R_s (Top-3)={b.iii.2,b.iii.1, b.iii.4}} that overlaps only with the bottom-3 ranked configurations query Q4, i.e., Q4_(bottom-3)={b.iii.3,b.iii.4,a.iii.2}. Thus, A(R_s [3])=1- (1/(11*3))=0.969.
To get a visualized intuition behind the conformance, The following figure shows the level of conformance of the top-ranked three configurations for the single-dimensional as well as pareto ranking criteria.
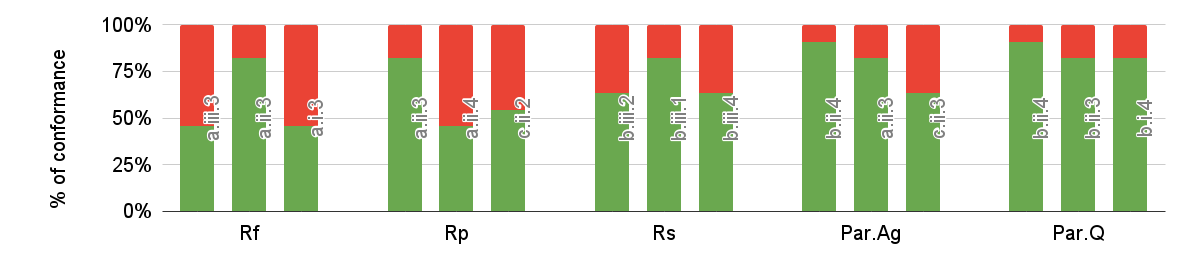
Example on one of the datsets (100M):
Table below shows the “confidence” ratios calcuated for all the ranking criteria (i.e, individual R_f, R_s,R_p, and combined AVG, WAvg, Rta). The table show the top-3 ranked configurations for each criteria, alongside all the the benchmark queris ranking of these configurations. The column “rank > 22” checks whehther these configurations opted by each criteria are not worst than the 22 bottom-ranked configurations according to the queries. Notably, this 22 is arbitraily used, but we can use any number restricting** or *relaxing the confidence calculation in the formula. In these sheets, you can find other examples of calculating the confidence with different h-bottom values other than 22 example.
| Conformance of each Ranking Criteria | rank > 17 | A(R) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100M | Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 | Q11 | ||
| Rf | |||||||||||||
| a.iii.3 | 24 | 17 | 25 | 21 | 21 | 23 | 14 | 33 | 16 | 17 | 9 | 6 | 0.42 |
| a.ii.3 | 22 | 11 | 14 | 1 | 13 | 20 | 13 | 13 | 4 | 7 | 14 | 2 | |
| a.i.3 | 23 | 25 | 21 | 5 | 19 | 24 | 16 | 20 | 8 | 12 | 15 | 4 | |
| Rp | |||||||||||||
| a.ii.3 | 22 | 11 | 14 | 1 | 13 | 20 | 13 | 13 | 4 | 7 | 14 | 2 | 0.39 |
| a.ii.4 | 19 | 20 | 20 | 2 | 18 | 21 | 15 | 18 | 6 | 11 | 17 | 5 | |
| c.ii.2 | 3 | 21 | 15 | 13 | 15 | 12 | 25 | 8 | 25 | 28 | 28 | 6 | |
| Rs | |||||||||||||
| b.iii.2 | 5 | 19 | 23 | 25 | 14 | 15 | 9 | 15 | 20 | 13 | 13 | 3 | 0.30 |
| b.iii.1 | 16 | 14 | 13 | 33 | 7 | 14 | 10 | 23 | 10 | 10 | 7 | 2 | |
| b.iii.4 | 11 | 4 | 19 | 35 | 17 | 18 | 11 | 29 | 3 | 5 | 8 | 4 | |
| Pareto_agg | |||||||||||||
| b.ii.4 | 9 | 8 | 9 | 22 | 1 | 7 | 5 | 14 | 1 | 6 | 2 | 6 | 0.21 |
| a.ii.3 | 22 | 11 | 14 | 1 | 13 | 20 | 13 | 13 | 4 | 7 | 14 | 2 | |
| c.ii.3 | 14 | 12 | 1 | 7 | 3 | 1 | 25 | 3 | 25 | 21 | 20 | 5 | |
| Pareto_Q | |||||||||||||
| b.ii.4 | 9 | 8 | 9 | 22 | 1 | 7 | 5 | 14 | 1 | 6 | 2 | 2 | 0.15 |
| b.ii.3 | 12 | 1 | 7 | 30 | 6 | 10 | 6 | 21 | 2 | 3 | 4 | 6 | |
| b.i.4 | 10 | 2 | 12 | 24 | 2 | 9 | 3 | 28 | 7 | 4 | 3 | 5 | |
** Note: the results are calculated by minusing the non-conformance shown in the table from the full percentage 100% of conformance (as will be shown in the table below for all the criteria and over all the datasets), as per equation of Conformance measure (equation 1 in this page).
Note that: the above results show the conformance for the configurations considering the Hive backend as a 5th stroage backend. However, for consistency we ommitted Hive from the calculations and kept only the HDFS file formats (CSV, Avro, ORC, and Parquet). Thus, we have new calculations and the configurations become 36 instead of 45 (i.e., by excluding configurations that include Hive as a storage backend).
The following table shows the conformance of each ranking criterion top-3 configurations not being worse than the worst the 17 ranked configurations (i.e., better than the 17 ones, half of the distri-bution) according to the queries’ ranked sets.
| Ranking Criterion | 100M | 250M | 500M |
|---|---|---|---|
| R_f | 58% | 82% | 70% |
| R_p | 61% | 70% | 58% |
| R_s | 70% | 79% | 79% |
| Pareto_Agg | 79% | 100% | 82% |
| Pareto_{Q} | 85% | 100% | 97% |
All the selected ranking criteria perform very well for all the datasets. However, the single-dimensional criteria Rf , Rp, and Rs have lower conformance than the one based on Pareto. For instance, in the 100M, 250M, and 500M datasets, ParetoAgg. has a conformance of 79%, 100%, and 82%, respectively. The same pattern repeats with the ParetoQ version (with 85%, 100%, and 97%, respectively). In contrast, single-dimensional ranking criteria have relatively lower conformance of 58%, 82%, and 70% for Rf , 61%, 70%, and 58% for Rp, and 70%, 79%, and 79% for Rs, accordingly.
The Conformance Figure shown above also depicts the level of conformance in green color, for the top-3 ranked configuration combinations. We can see that the level of conformance in the pareto raking criteria (multi-dimensional) is higher than the Rf, Rp, Rs single-dimensinal ranking criteria.
The main reason behind these results is that single-dimensional criteria do not consider trade-offs across experimental dimensions, ultimately selecting the configuration that may under-perform in some queries. Meanwhile, Pareto-based ranking considers those trade-offs while optimizing all the dimensions simultaneously.
2- The Coherence Measure:
To measure the coherence of each ranking criterion, we opt for Kendall index, which counts the number of pairwise disagreements between two rank sets: the larger the distance, the more dissimilar the rank sets are. Notably, we assume that rank sets have the same number of elements. Kendall’s distance between two rank sets R_1 and R_2, where P represent the set of unique pairs of distinct elements in the two sets can be calculated using the following equation:
Example of Coherence
For instance, the Kendall’s index (K) between R_s (Top-3) for 100M and 250M is 0.33 (See table above of best_ranked_configuration for the individual criteria in the page). Indeed, there was only one disagreement out of three configurations observations (i.e, the cofiguration b.ii.1 in the 250M dataset ranked better than b.iii.2).
Table below shows the K index as per Equation (2) in this page. All the criteria show a good coherence across different scales of the datasets (the lower the better). Indeed, scaling the datasets up, we realize small distances (i.e. indicating low changes in the ranking ordinals) for both individual and combined ranking criteria. Intuitively, if across scalability, the opted ranking criterion has high Kendall’s index (i.e., high disagreement of the same ranking), it indicates the inappropriateness for ranking to describe the performance.
To give the intuituion behind the coherence metric by showing the top-10 ranked configuration for the same ranking criterion(R_p) (i.e., )
and across three different data scales. We can see examples of pairwise disagreements that occur by scaling from 100M to 250M, and also from 100M to the 500M dataset. For instance, in (100M -to-250M ), b.ii.3 was at the 10th rank in 100M, while being swapped to be at the 1st position in the 250M, and the 1st ranked configuration (a.ii.3) in the 100M swapped to be at the 8th rank in the 250M. Similar kind of disagreements are shown in the (100M-to-500M) scale-up transition.
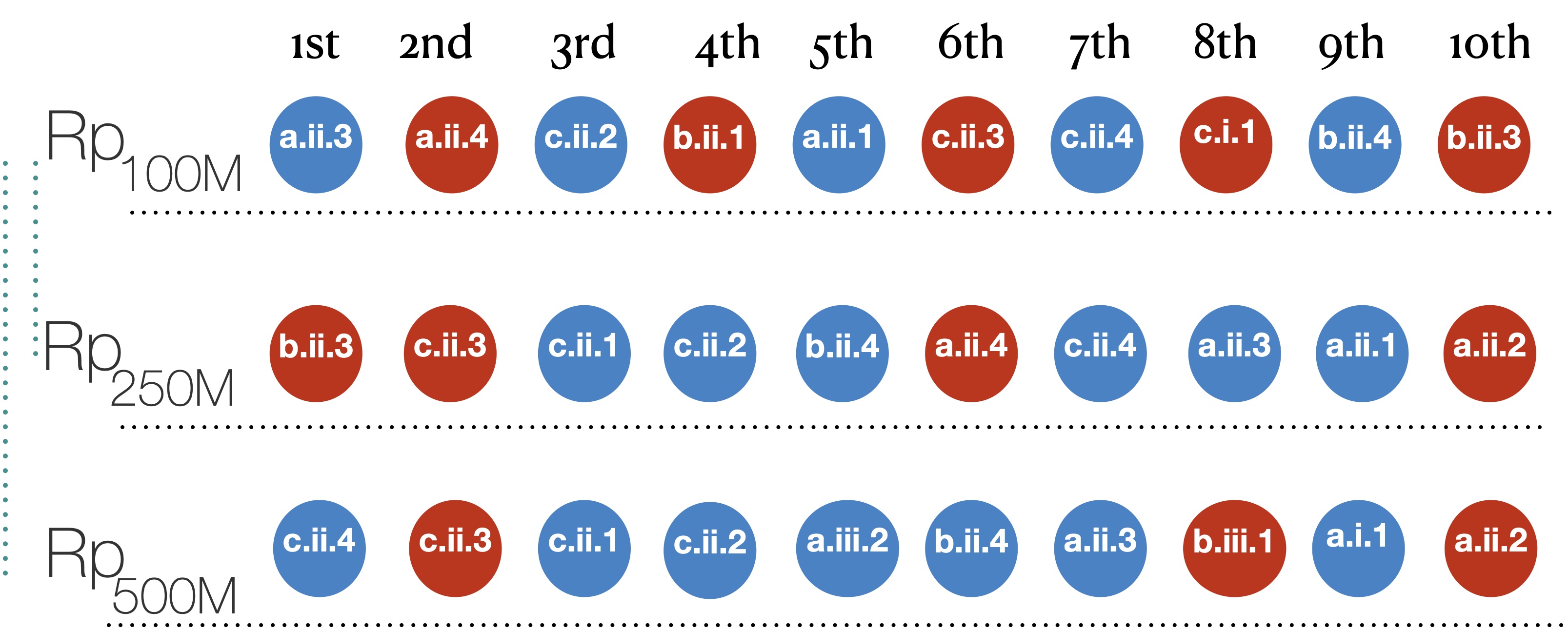
Please note the swaps of colors, it starts as blue, red, blue,…, however with moving to larger data scales, color disagreements already occur there with the mentioned swaps.
| Dataset_i VS. Dataset_j | R_f | R_s | R_p | Pareto_Agg | Pareto_Q |
|---|---|---|---|---|---|
| 100M vs 250M | 0.13 | 0.18 | 0.06 | 0.19 | 0.24 |
| 100M vs 500M | 0.16 | 0.29 | 0.06 | 0.19 | 0.24 |
| 250M vs 500M | 0.13 | 0.19 | 0.07 | 0.13 | 0.18 |
The above table shows the results where the reading key is the lower, the better( i.e., high Kendall’s index means high disagreement across rank set). All the ranking criteria show high coherence across different scales of the datasets. Indeed, scaling the datasets does not excessively impact the rank sets’ order in all the ranking criteria.
Note All the scripts for calculating the Kendall’s index can be found in the scripts in this repo, and attached with the calculations sheet.