SPARKSQL RDF Benchmark.
A systematic Benchmarking on the performance of Spark-SQL for processing Vast RDF datasets
- Home
- Bench-Ranking
- Ranking Criteria
- Ranking Goodness
- Project Source Code
- Results
- Benchmark Datasets
- Download Logs
This project is maintained by DataSystemsGroupUT
Reproducibility of Optimized SPARQL Query Execution Using Spark-SQL Experiements (Distributed)
Hardware and Software Configurations: Our experiments have been executed on a bare metal cluster of four machines with a CentOS-Linux V7 OS, running on a 32-AMD cores per node processors, and 128 GB of memory per node, alongside with a high speed 2 TB SSD drive as the data drive on each node. We used Spark V2.4 to fully support Spark-SQL capabilities. We used Hive V3.2.1. In particular, our Spark cluster is consisted of one master node and three worker machines, while Yarn is used as the resource manager, which in total uses 330 GB and 84 virtual processing cores.
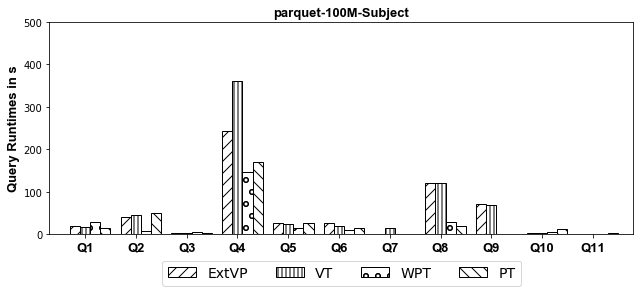
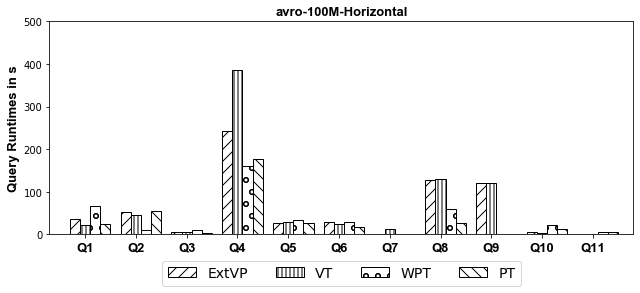
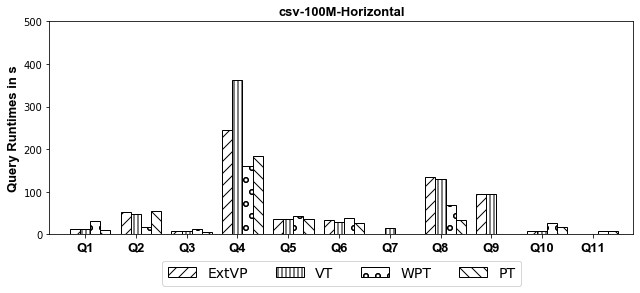
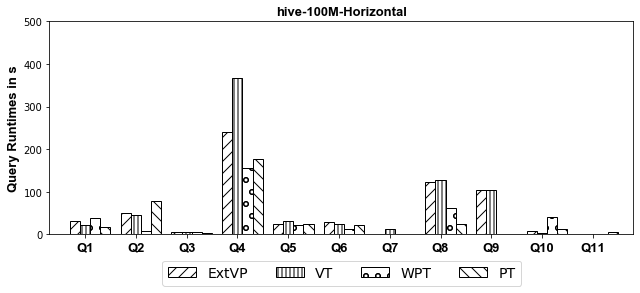
Experiments: we investigate systematically the pitfalls behind implementing these optimizations over SparkSQL. We compare ExtVP with VT and WPT with PT considering (1) three different partitioning techniques, i.e., Horizontal, Subject-based, and Predicate-based partitioning and (2) five different storage formats, i.e., ORC, CSV, Parquet, Avro, and Hive.
- Notes:
- We also provide Long and Short Running Query Result Figures that looks clearer here
- We provide the the aggregated figures of comparing the performance of ExtVP VS VP of Sample Queries here
- We provide the the figures thatshow the effect of complex solution space of (schema,partitioning, and storage) on the schema advancements peformance here
Execution Runtimes (100M Triples Dataset Results)
-
100M Results[Horizontally Partitioned]
-
AVRO
- CSV
- Hive
- ORC
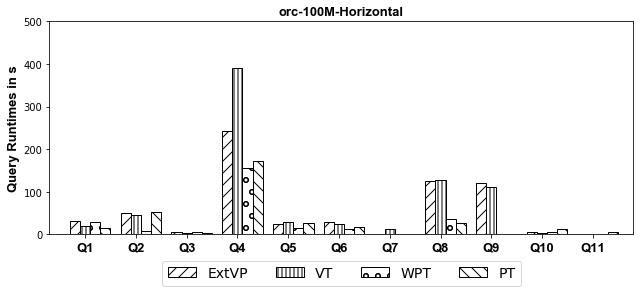
- Parquet
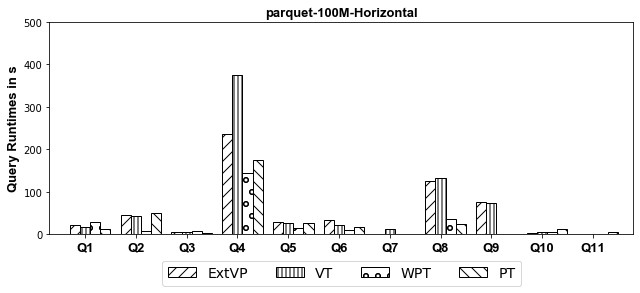
-
100M Results[Predicate-Based Partitioned]
-
AVRO
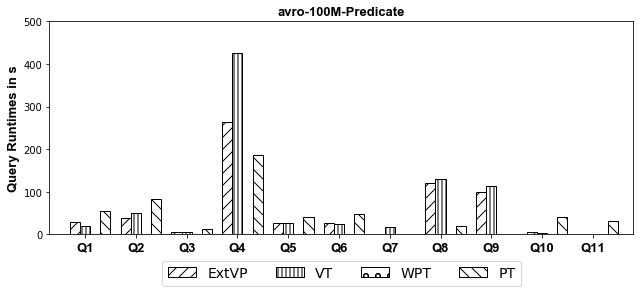
- CSV
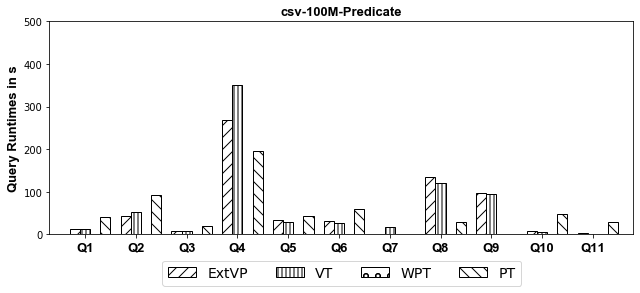
- Hive
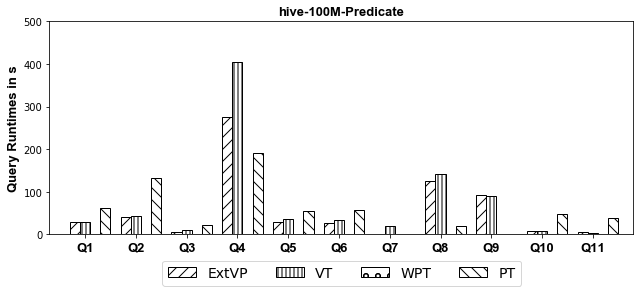
- ORC
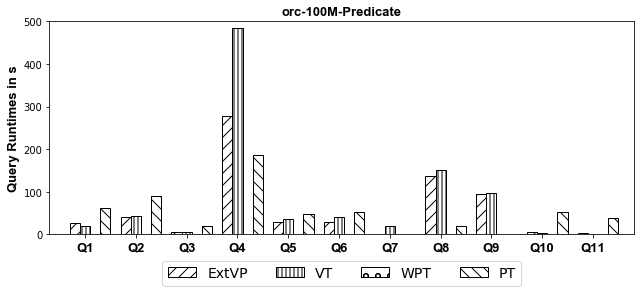
- Parquet
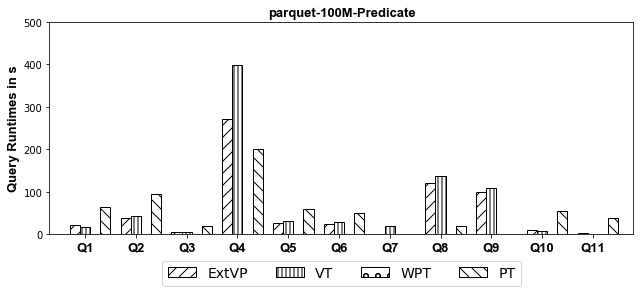
-
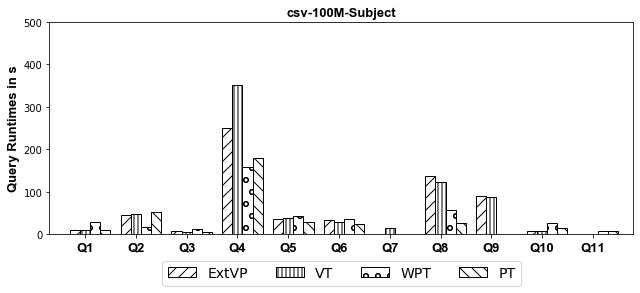
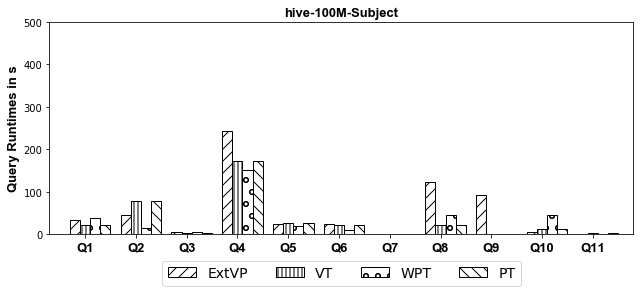
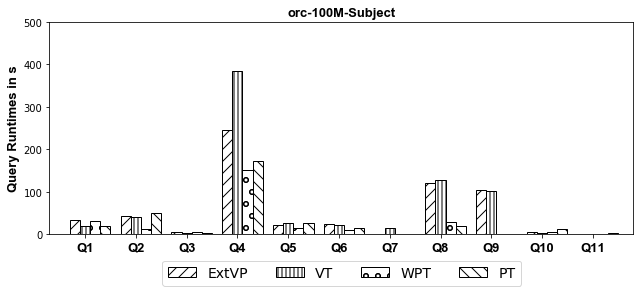
100M Results[Subject-Based Partitioned]
-
AVRO
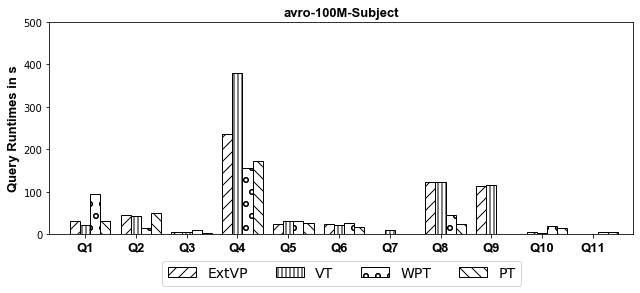
- CSV
- Hive
- ORC
- Parquet