SPARKSQL RDF Benchmark.
A systematic Benchmarking on the performance of Spark-SQL for processing Vast RDF datasets
- Home
- Bench-Ranking
- Ranking Criteria
- Ranking Goodness
- Project Source Code
- Results
- Benchmark Datasets
- Download Logs
This project is maintained by DataSystemsGroupUT
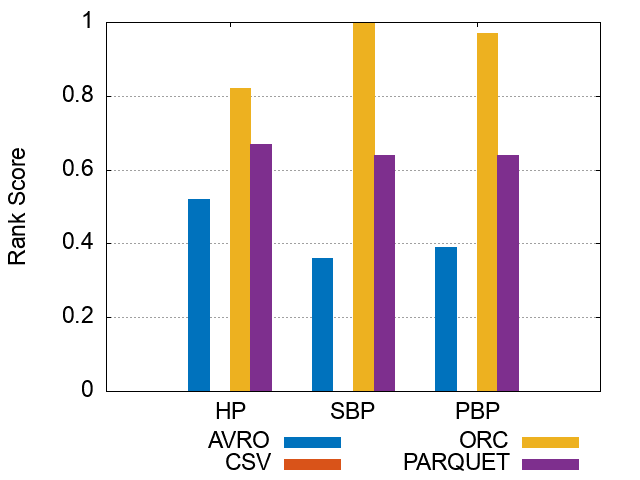
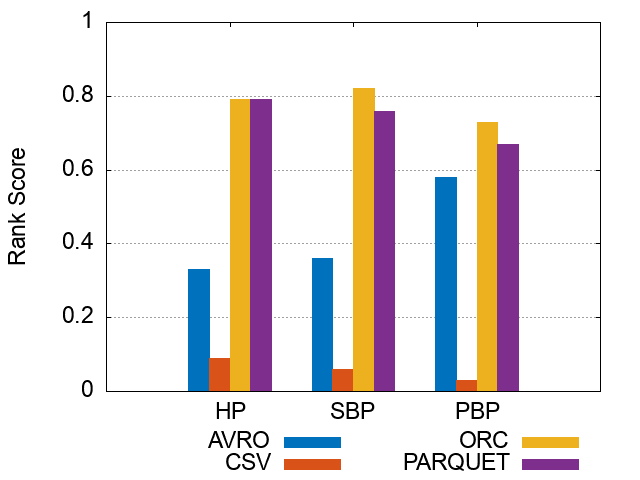
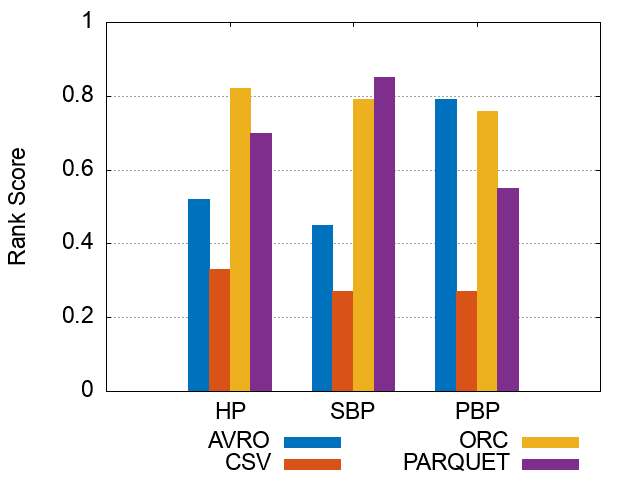
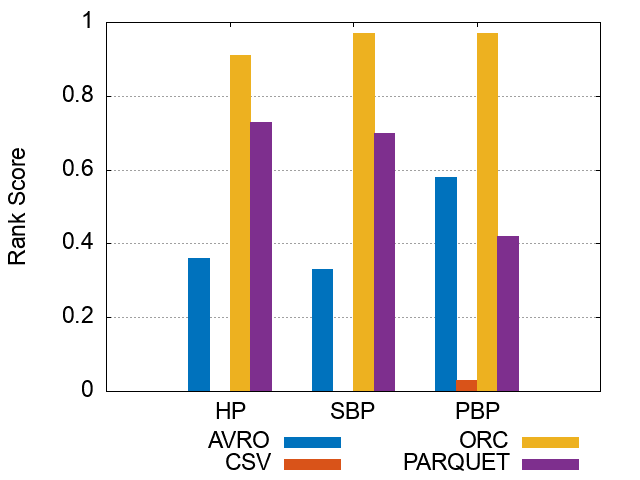
Figures of experiment results for Storage Backends
These figures show the comparative representation of Storage backends (i.e. HDFS [CSV,AVRO, PARQUET, ORC], and HIVE) for 100M, 250M, and 500M respectively.
*Please note that the following ranking figures include Hive as a 5^th storage backend. However, we have excluded Hive and for simpolicity kept only the HDFS storage file formats (CSV, AVro, ORC, and Parquet). Figures of ranking the storage dimension (excluding Hive) can be shown here.
100M Triples Storage BackendsRanking Scores
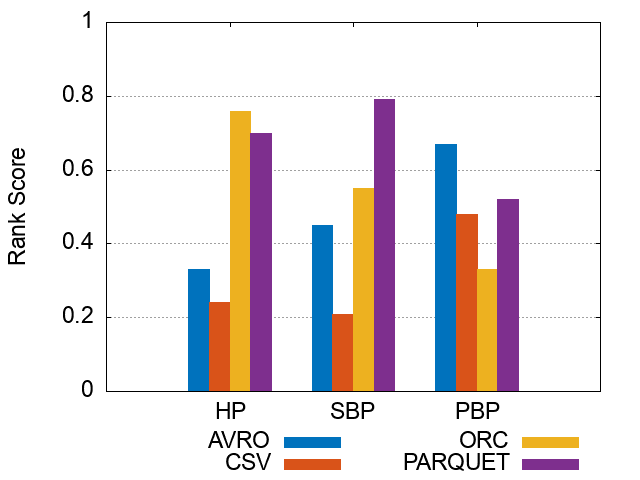
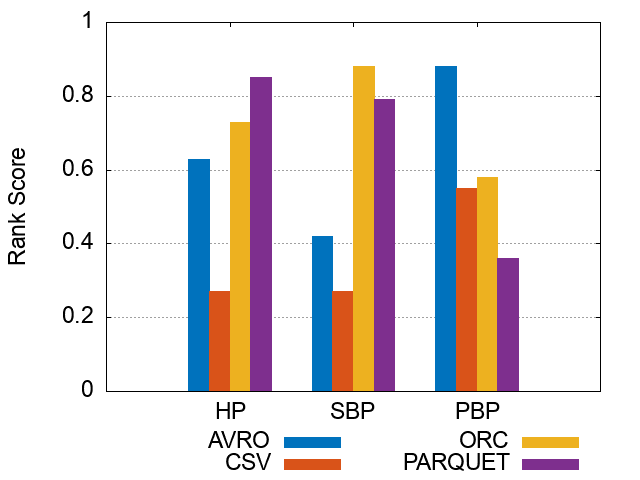
250M Triples Storage Backends Ranking Scores
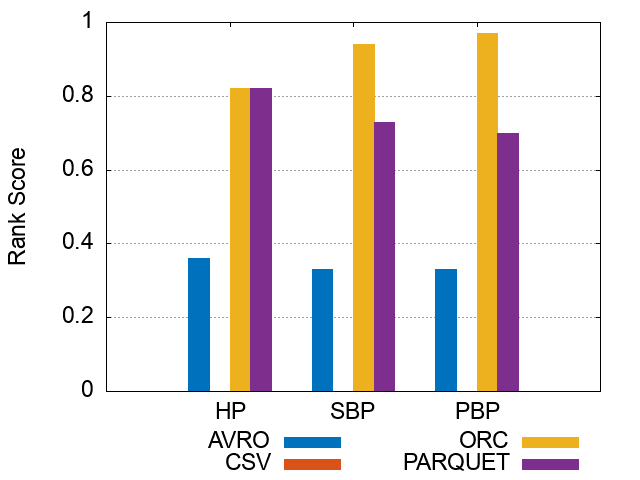
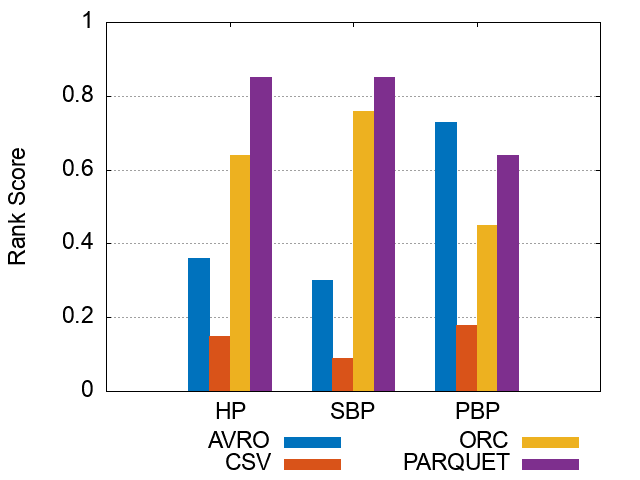
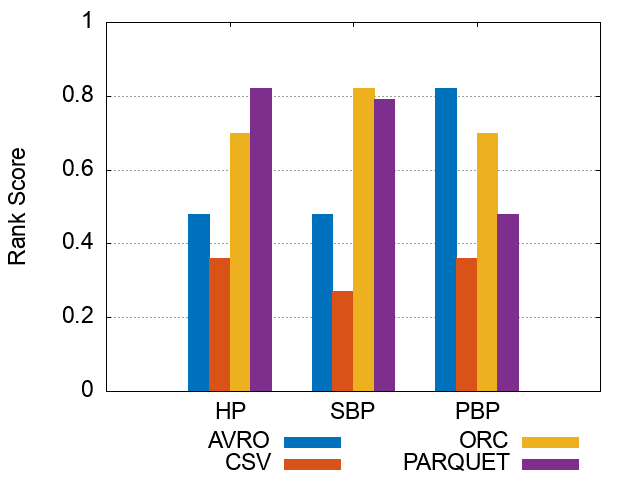
500M Triples Storage Backends Ranking Scores