SPARKSQL RDF Benchmark.
A systematic Benchmarking on the performance of Spark-SQL for processing Vast RDF datasets
- Home
- Bench-Ranking
- Ranking Criteria
- Ranking Goodness
- Project Source Code
- Results
- Benchmark Datasets
- Download Logs
This project is maintained by DataSystemsGroupUT
Figures of experiment results for Partitioning
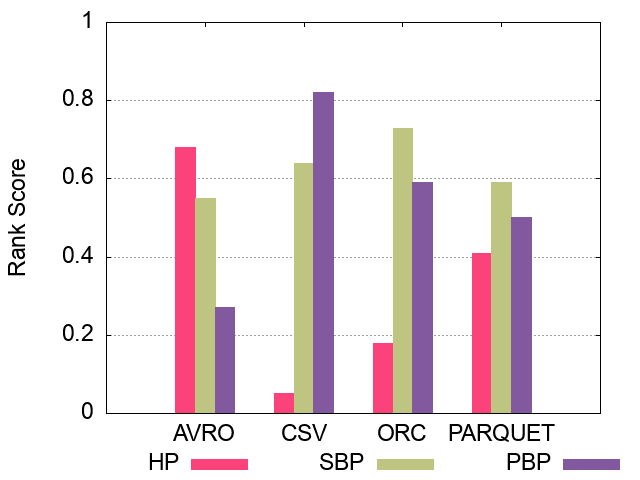
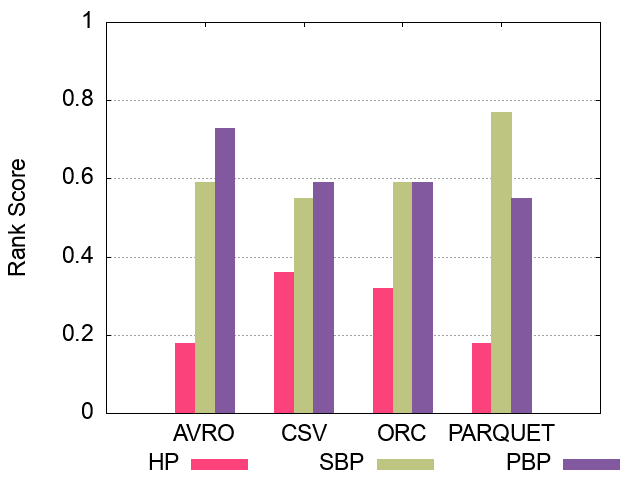
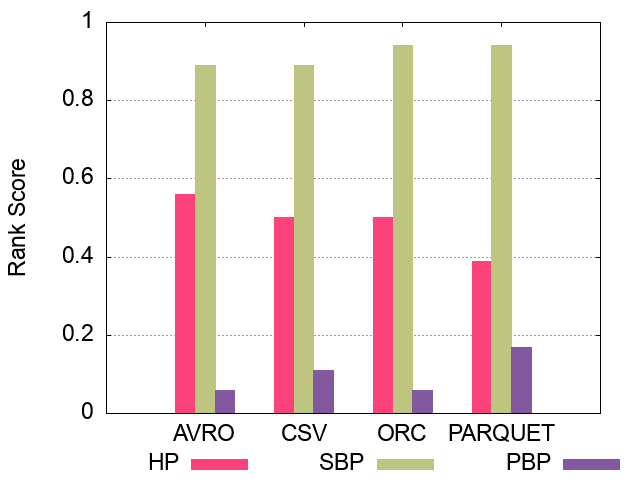
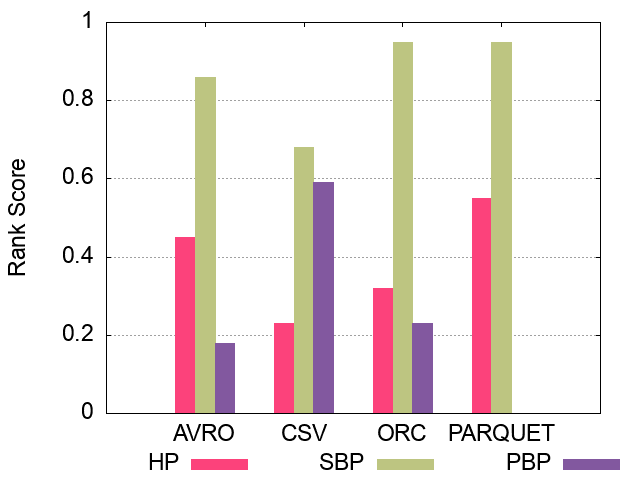
The following figures show the comparative representation of partitioning techniques (i.e. Horizontally, Subject-based, Predicate-based) for 100M, 250M, and 500M respectively (Excluding Hive).
100M Triples Partitioning techniques Ranking Scores
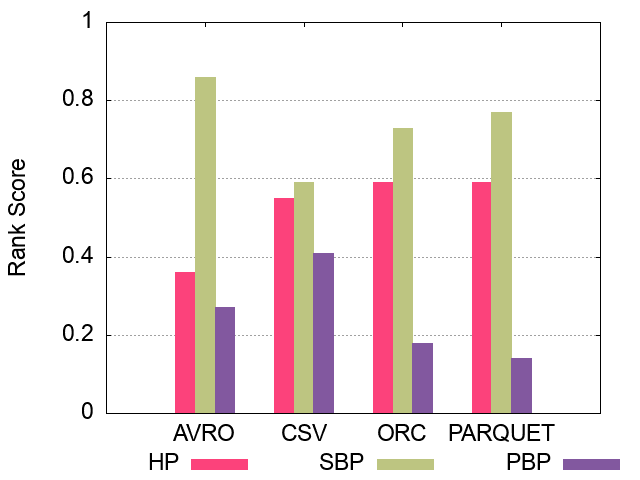
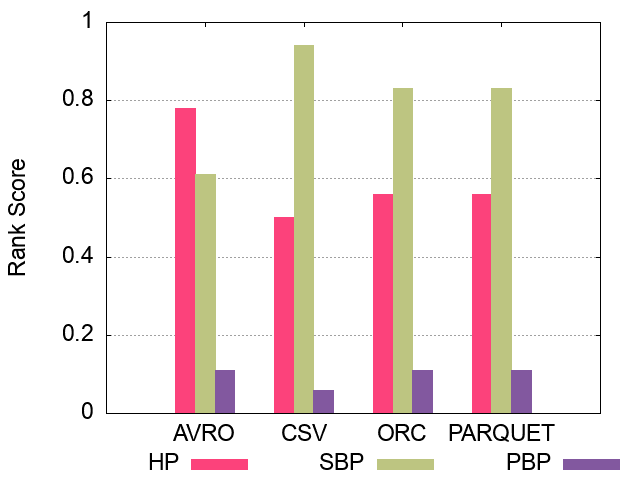
250M Triples Partitioning techniques Ranking Scores
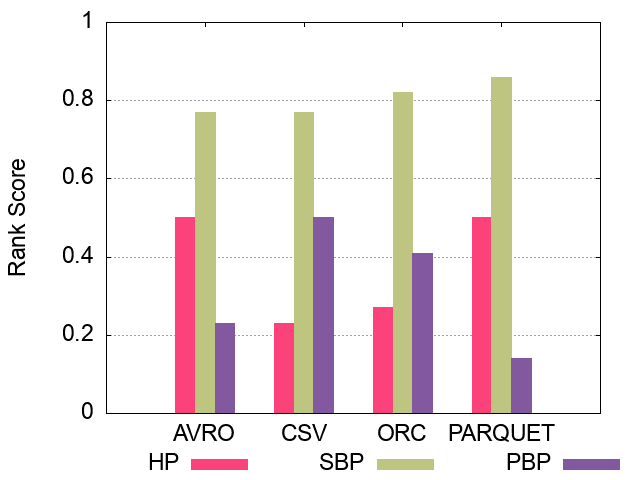
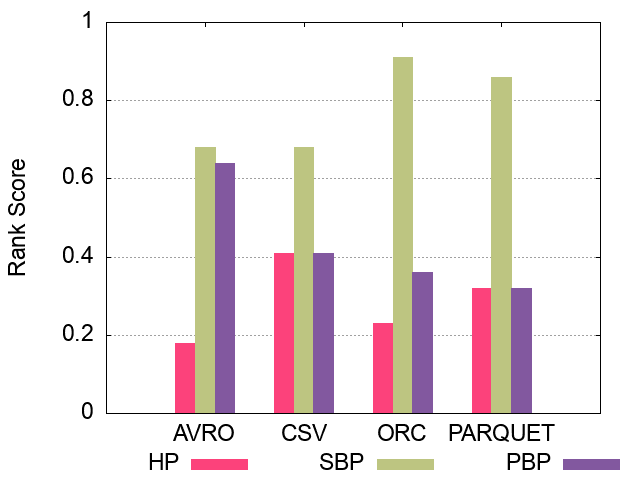
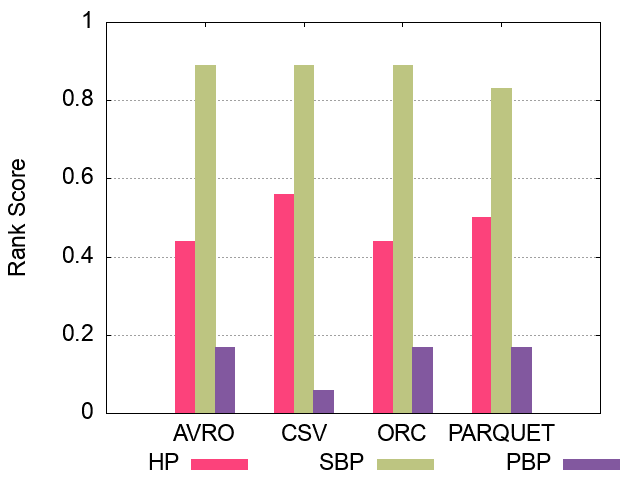 <
#### 500M Triples Partitioning techniques Ranking Scores
<
#### 500M Triples Partitioning techniques Ranking Scores