A systematic Benchmarking on the performance of Spark-SQL for processing Vast RDF datasets
This project is maintained by DataSystemsGroupUT
We start by discussing the descriptive analysis by discussing the average query runtimes figures for the benchmark queries. We further follow these descriptive results with respective diagnosis analysis for answering the ‘why?’ question for those results.
SP2Bench Querie Averge runtime figures can be seen in this link.
From the figures, we can observe that queries Q1,Q3,Q10, and Q11 are the least impactful queries (i.e., have the lowest running times). Thus, we call these queries short-running queries. On the other hand, queries Q2,Q4, and Q8 have the longest runtimes. The remaining queries Q5, Q6 ,Q7,and Q9 are medium-running queries.
In the following, we focus our analysis on the longest running queries, as they may hide interesting insights about the approach limitations.
The previous observation is only valid with neglecting the bad performance of the CSV and Avro in the ST schema. However, it gives a clear answer of the impact of storage impact on our observations.
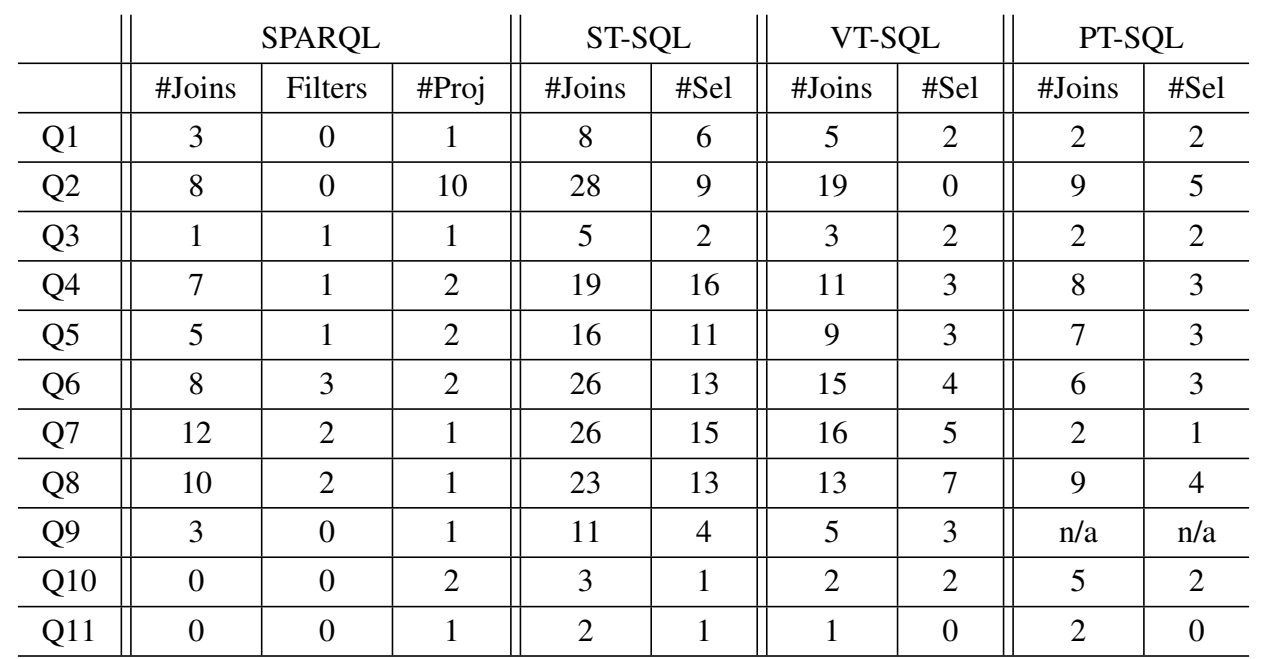
Moving to the diagnostic analysis, we try to explain the previous observations by analyzing the query complexity (Shown in the table here) and using our knowledge about Spark and the experimental dimensions, i.e. relational schema, partitioning techniques, storage backends. We try to provide diagnostic analysis concerning these dimensions rather than investigating each single query result.
Regarding the relational schema comparison, we can bserve that the ST schema is mostly the worst performing schema. Indeed, the ST schema is the one that requires the maximum number of self-joins (see the query complexity table, ST-SQL column). Moreover, ST schema single table is the largest table even after partitioning.
Whereas, the VT schema is mostly the best performing schema, specially when we scale up to higher datasets. The reason behind this is that VT tables tend to be smaller than other relational schema tables. Thus, Spark query joins have smaller intermediate results in the shuffle operations. In addition, VT tends to be more and more efficient with queries with small number of joins (i.e. BGB triple patterns).
While, the PT schema is yet a strong competitor to the VT schema, since it is the schema that requires the minimum number of joins while translating SPARQL into SQL. Indeed, PT in the single machine experiments achieved the highest ranks in the majority of query executions. However, scaling up the experiment sizes, PT schema starts to incur larger intermediate results with higher shuffling costs that degrade its performance. Moreover, partitioning PT schema over Predicate (PBP) or Horizontally (HP) gives a negative effect on the PT schema performance, especially with SP2Bench query set that is highly ‘subject’-oriented. We specify this with the reasoning about the impact of partitioning in our experiments.
Regarding the partitioning techniques comparison, in general, the Subject-based partitioning approach tends to considerably outperform its other partitioning opponents. Particularly, it directly outperforms the HP approach, leaving the PBP technique in the worst rank. The reason behind this is that most of the queries in SP2Bench are on shape of ‘Star’ or ‘Snowflake’ which are mostly oriented to the RDF subject as the joining key. Indeed, partitioning by subject allocates the triples with the same subject on the same machine reducing data shuffling to the minimum, and maximizing the level of parallelism by all workers.
Whereas, this is not satisfied in the Horizontal-based approach, as it splits the tables and only cares about distributing them in a balanced way as much as possible regardless grouping of the rows of the same subject on the same machine.
Finally, the predicate-based approach presents the highest degree of shuffling while joins are run by Spark-SQL in most of the SP2Bench. Therefore, Predicate-based technique are not recommended when evaluating ‘subject-oriented’ queries. Moreover, Predicate-based partitioning is the most unbalanced load partitioning technique with the highest data skewness. Since our SP2Bench RDF datasets have some predicates with few triples/table entries (i.e. subClassOf), while others have the most portions of the RDF graph (i.e. creator, type, and homepage). Hence, this unbalanced nature leads to stragglers and inefficient join implementations in Spark-SQL.
What we observed is that, columnar file formats of HDFS storage backend are outperforming the others. In particular, ORC is the best performing storage format followed by Parquet. While Hive directly follows them.
Whereas, Avro and CSV file formats of HDFS are the worst-performing backends. Interestingly, we can observe that Avro outperforms the other storage formats in the PBP partitioning technique.
The reason behind these results is that, most of the SP2Bench queries are with a small number of projections as shown in complexity table menioned above. Thus, columnar file storage backends perform better since they have to scan only a subset of the columns with filtering out unnecessary columns for the query. Hive is consistently following them. On the other side, the textual uncompressed \textit{CSV} and the \textit{row-oriented} Avro file formats are shown to have the lowest performing storage options, respectively.
{kind=link}